Large multimodal models (LMMs) have proven flexible and generalisable across many tasks and fields. Although they have strong potential to aid scientific research, their capabilities in this domain are not well characterised. A key aspect of scientific research is the ability to understand and interpret figures, which serve as a rich, compressed source of complex information.
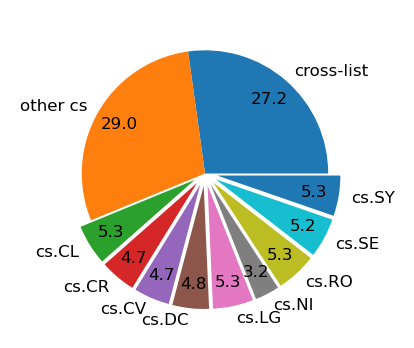
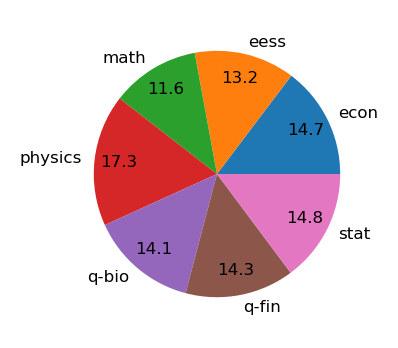
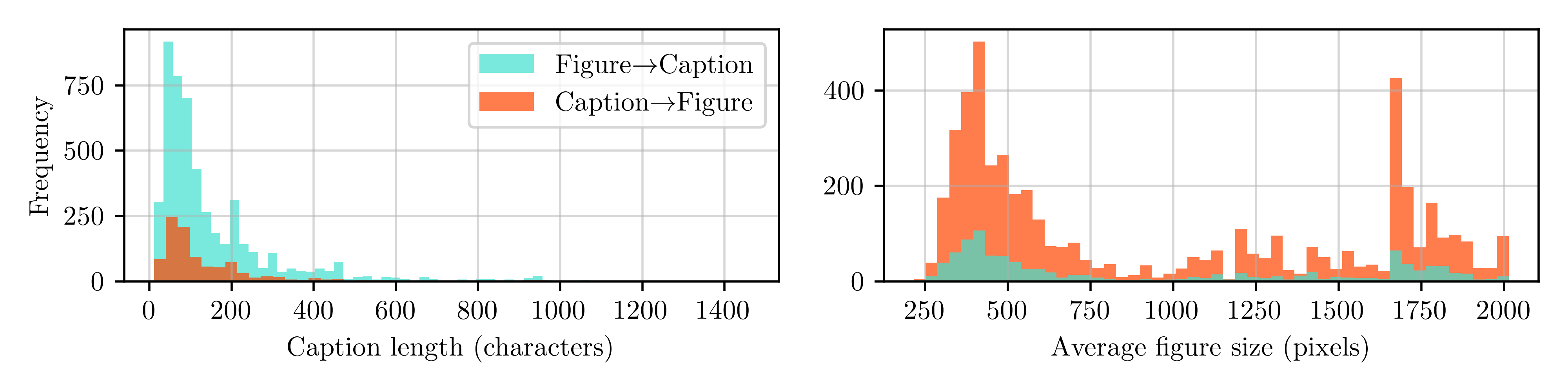
We introduce SciFIBench (Scientific Figure Interpretation Benchmark), a benchmark consisting of 2000 questions split between two tasks across 8 categories. The questions are curated from arXiv paper figures and captions, using adversarial filtering to find hard negatives and human verification for quality control. We evaluate 28 LMMs on SciFIBench, finding it to be a challenging benchmark.
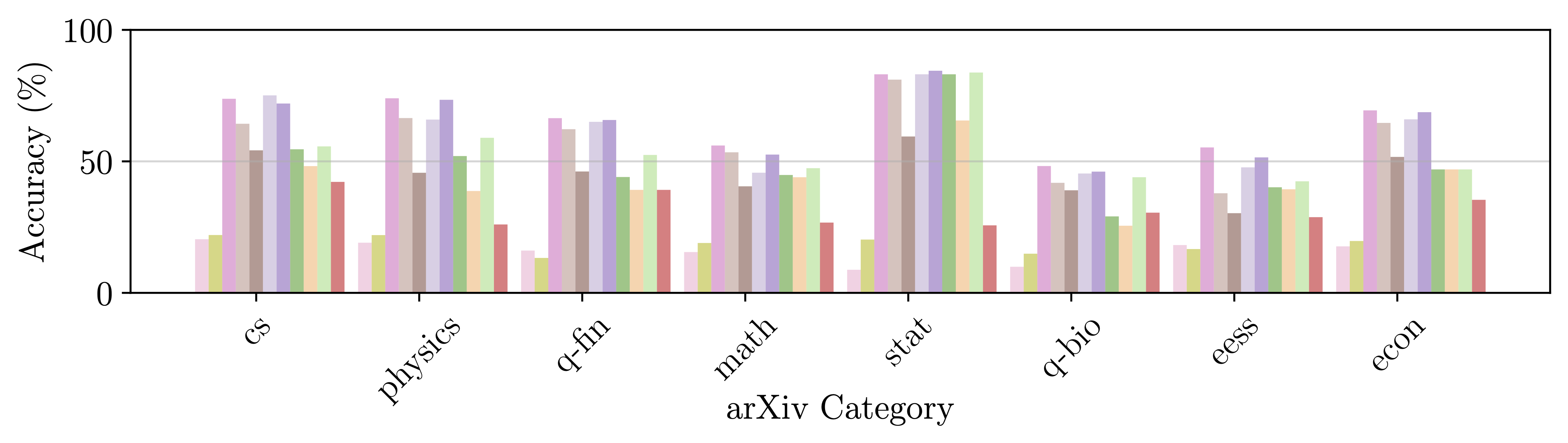
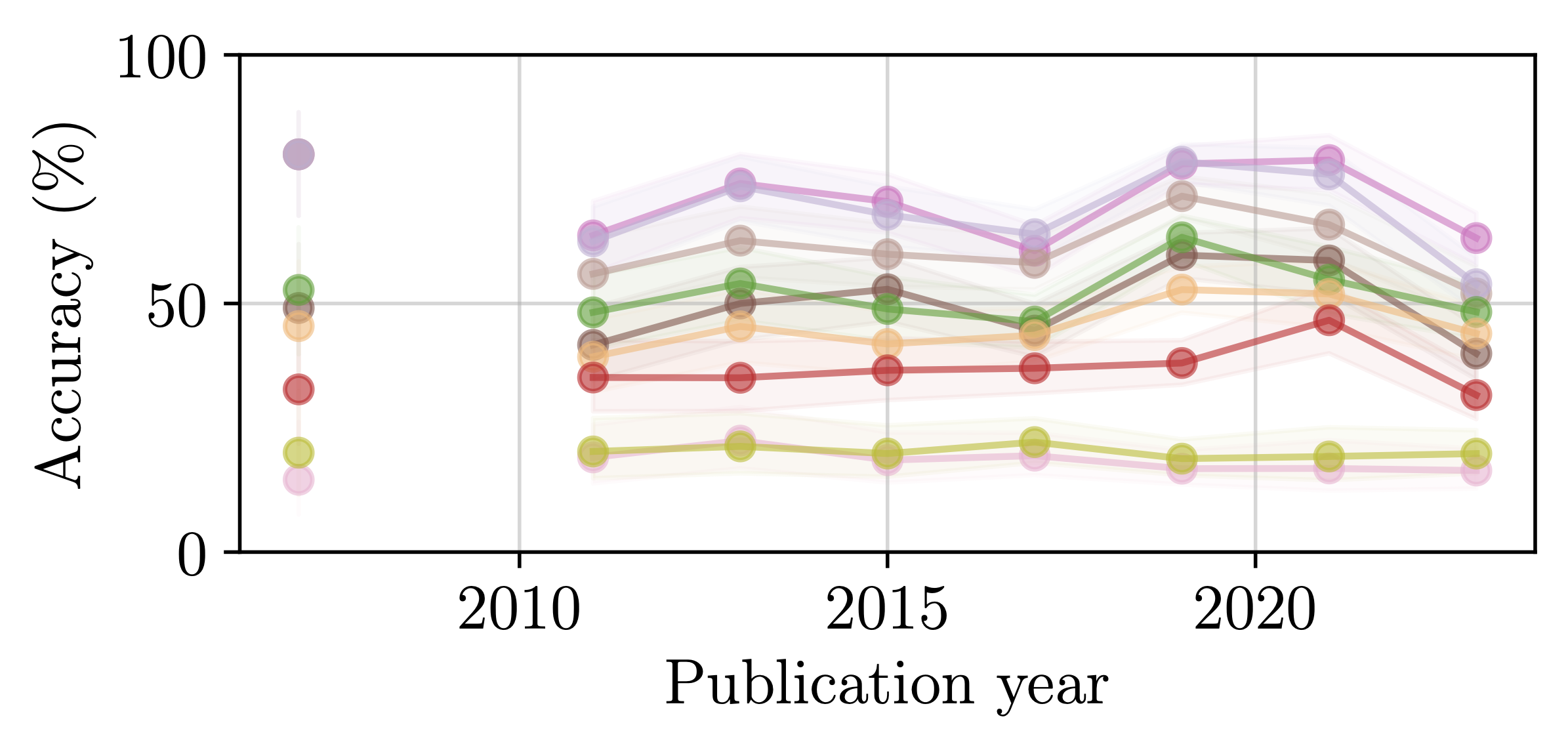
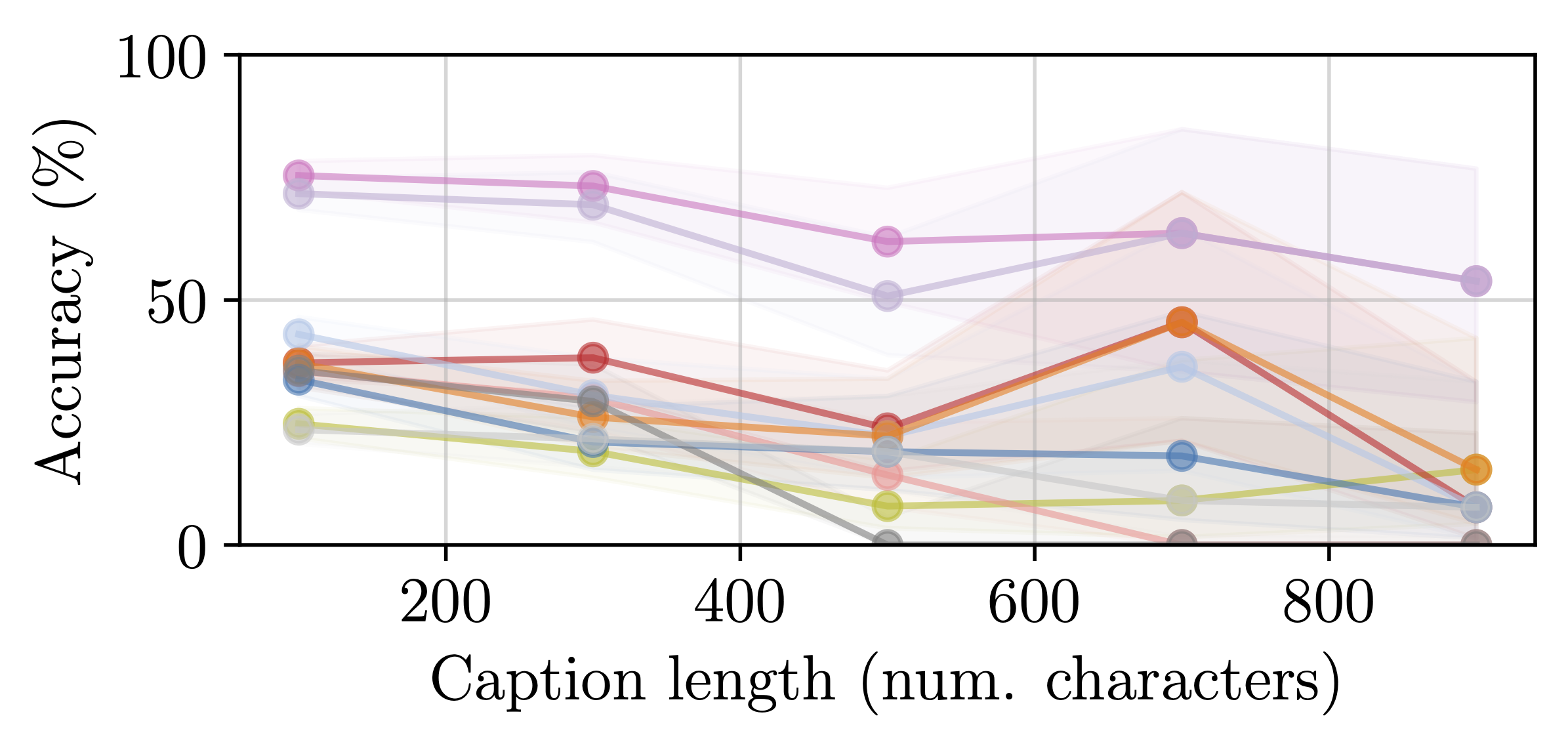
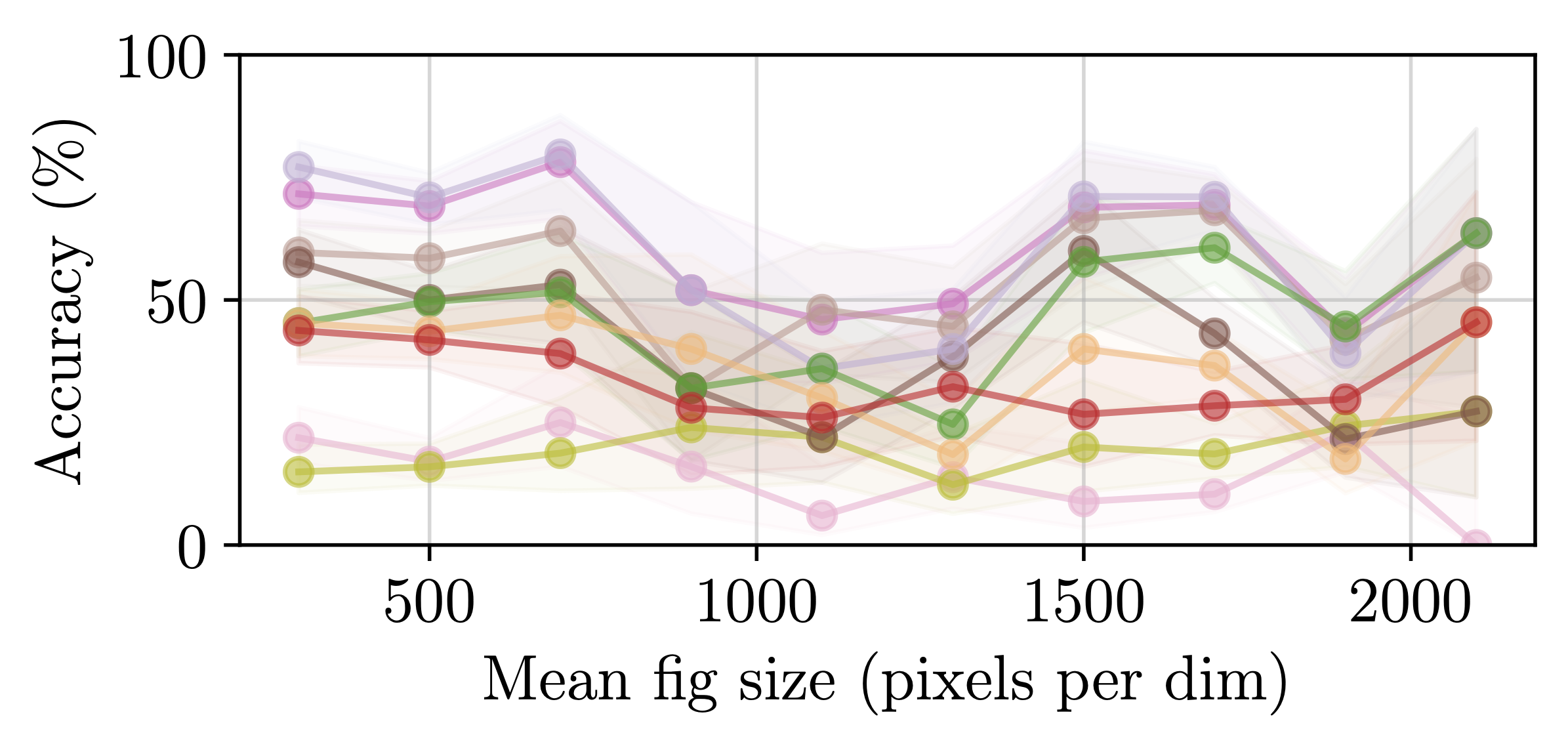
Additionally, we conduct an analysis of model performance across different question properties, explore caption generation capabilities and investigate the alignment and reasoning faithfulness of the LMMs on augmented question sets from our benchmark.